Datenquellen
Die Kernfunktion der DDS ist es, Daten aus existierenden Datenquellen aufzuarbeiten und für die Nutzer verfügbar zu machen.
Alle Datenpunkte und deren Varietäten, sowie deren Metadaten, werden beim Datenpunkt-Import aus den Quelldatenbanken ins DDS übertragen. Das passiert je nach Typ der Datenquelle entweder in regelmäßigen Abständen oder manuell.
Berechtigungen im Kontext von Datenquellen
Es ist möglich, Berechtigungen auf den Kontext von Datenquellen einzuschränken. Das wichtigste Beispiel dafür ist wohl, die maximale Vertraulichkeit von abgefragten Daten je nach Datenquelle einzuschränken.
Datenpunkt- und Datenvarietäten-Schemata
Jeder Datenquelle wird genau ein Datenpunkt- und genau ein Datenvarietäten-Schema zugewiesen. Die Auftrennung ist notwendig, da Metadaten sich zwischen Datenpunkten und Varietäten unterscheiden, z.B. Techn. Name für Datenpunkte und Archiv-Code für Varietäten.
Relation zu Metametadaten
Jedes Metametadatum kann beliebig vielen Datenqullen über ihre jeweiligen Schemata (Datenpunkt oder -varietät) zugewiesen werden, aber nur einem von beiden abhängig vom Entitätstyp des Metametadatums. Diese Zuweisung kann im Editierdialog des Metametadatums durchgeführt werden.
In der Datenpunktsuche werden die zugewiesenen Metametadaten dann als Filter in der Suche angezeigt.
In der nachfolgenden Abbildung der Datenpunktsuche ist eine virtuelle Datenquelle im Datenquellen-Filter ausgewählt. Die Filter werden demnach auf die von der virtuellen Datenbank benutzten Metametadaten reduziert:
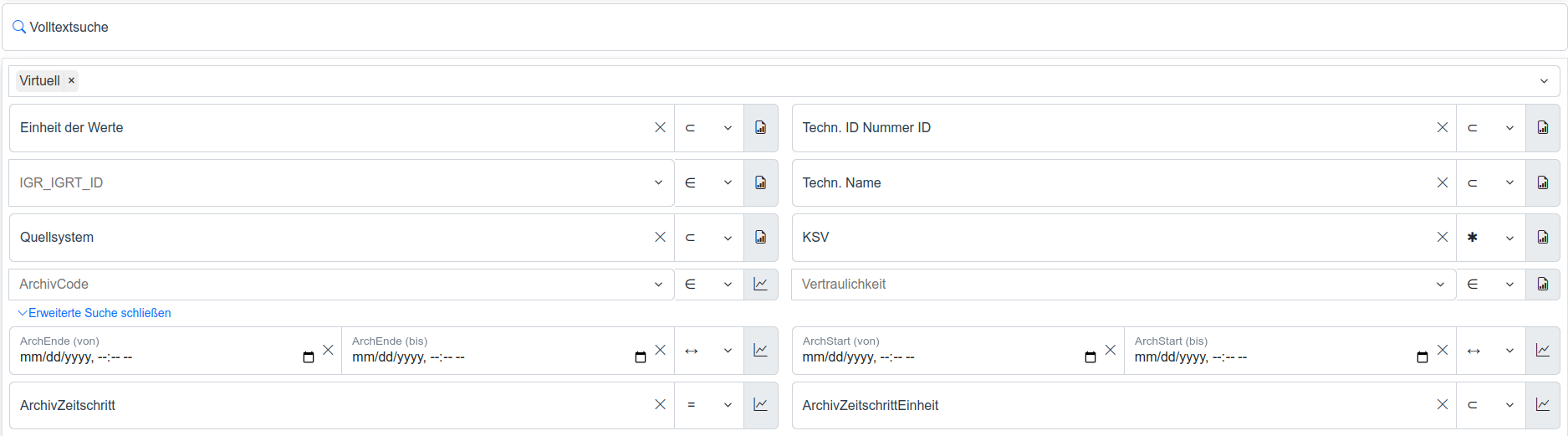
Abb. 1: Virtuelle Datenquelle ist in der Suche ausgewählt
Liste aller Metadaten von Datenquellen
- Datenquellentyp: Interner Bezeichner für diese Datenquelle. Üblicherweise identisch zum Kurznamen.
- Kurzname: Ein kurzer (üblicherweise Ein-Wort-Akronym) Bezeichner einer Datenquelle. Dieser Bezeichner wird z.B. in Multi-Auswahlboxen verwendet, in denen Datenquellen ausgewählt werden können.
- Langname: Eine etwas längere Bezeichnung einer Datenquelle. Kann z.B. das voll ausgeschriebene Akronym sein.
- Datenpunkt-Anlegemethodik: Gibt an, wie neue Datenpunkte aus der Datenquelle in das System importiert werden.
- Automatisch bedeutet ein automatischer, regelmäßig stattfindender Import aus der Quelldatenbank.
- Import bedeutet ein Import aus Tabellendokumenten, der händisch oder automatisch durchgeführt werden kann.
- Manuell bedeutet, dass neue Datenpunkte ausschließlich über den Editier-Dialog angelegt werden können.
- Keine bedeutet, dass aus dieser Datenquelle nichts importiert wird (z.B. Export-Datenbank)
- Datenbanktyp: Welche Datenbank-Engine für die Quelldatenbank benutzt wird (Bsp. Oracle)
- Datenbankzugriff: Zugriffsweise auf die Quelldatenbank
- Tabellennamen: Namen der Tabellen in der Quelldatenbank, welche die relevanten Daten beinhalten
- Schemata: Name der Schemata, in denen die relevanten Tabellen in der Quelldatenbank liegen.
- Adapter für Zeitumstellung: Wie die Zeitstempel der Datenwerte aus dieser Datenquelle in den Standard von UTC-Millisekunden umgerechnet werden können
- Eingehend/Ausgehend: Ob diese Datenquelle für Import oder Export gedacht ist.
- Previewgrenze: Wie viele Datenwerte maximal pro Varietät in der Datenpreview geladen werden. Sollte nicht zu hoch sein, da ansonsten eine übermäßige Last für die Quelldatenbanken beim Previewen entsteht.
- OSGI-Key: Ein technischer Schlüssel aus dem Deployment der DDS, wird im Backend benutzt. Virtuelle DBs haben keinen OSGI-Key. Nach dem Anlegen nicht mehr editierbar.
- Link auf weiterführende Informationen: URL zu Ressource mit mehr Informationen.
- Datenschutzrelevante Themen: Insbesondere im Kontext der DSGVO
- Behandlung von Null-Werten: Welche Werte aus der Quelldatenbank werden als NULL-Werte interpretiert (Beispiel: Oracle setzt leeren Text gleich mit NULL)
- Exportspalten-Beschreibung: Informationen zu den Werten, die in der Exportdatenbank auf die reservierten Spalten
annotation_1bisannotation_4sowiemessagegeschrieben werden (das kann je nach Datenbank anders sein). Dient zur Hilfe
Parameter von Schemata
Beide Schemata haben jeweils diese Parameter:
- Langnamensmuster: Das hier eingetragene "Muster" wird benutzt, um den Langnamen des Datenpunkts bzw. der Datenvarietät aus deren Metadaten zu konstruieren. Der "Langname" wird dabei z.B. fett gedruckt in der Resultatsliste der Datenpunktsuche benutzt. (Details)
- Langnamensanmerkungsmuster: Der effektive Langname besteht aus dem Langnamensmuster + den hier konfigurierten Anmerkungen.
- Kurznamenmuster: Das Kurznamenmuster wird z.B. verwendet, um Varietäten in der Auswahlliste zu repräsentieren.
WARNING
Bitte beachten Sie, dass die meisten Attribute in dieser Liste nur zur Illustration und Kategorisierung dienen und Änderungen nicht die Funktionsweise der dahinterliegenden Quelldatenbank ändern.
Ausnahmen sind die folgenden:
- Kurzname und Langname (Anzeigenamen in der DDS)
- Alle Namensmuster (Beeinflusst, wie Datenpunkte und -varietäten Anzeigenamen zugewiesen werden)
- Previewgrenze
Übertragung von Muster in Anzeigenamen
Technische Details / Konstruktion der Bezeichner aus Metadaten
Zur Konstruktion wird im DDS der Apache Commons StringSubstitutor benutzt, wobei die aufgelösten Variablen die techn. Namen der Metametadaten sind.
Es ist empfehlenswert, Metadaten zu wählen, welche immer vorhanden sind. Wenn ein ungültiger Bezeichner eingetragen wird oder der Wert des Metadatums null ist, wird bei der Auflösung einfach leerer Text eingetragen.
Illustration der Funktionsweise:
Hier eine Beispielkonfiguration für die EWDB-Datenquelle.

Abb. 2: Langnamenkonfiguration für "EWDB"-Datenquelle
Für den Langnamen wird nur der techn. Name(DpTecName) verwendet, für die Anmerkungen dann noch die Einheit(DpUnit) und das Quellsystem(DpOriginSys).
Eckige Klammern haben im Apache StringSubstitutor keine syntaktische Bedeutung und werden somit einfach übernommen. Damit kann man Formatierung in den endgültigen String hineinbringen, zur leichteren Lesbarkeit.
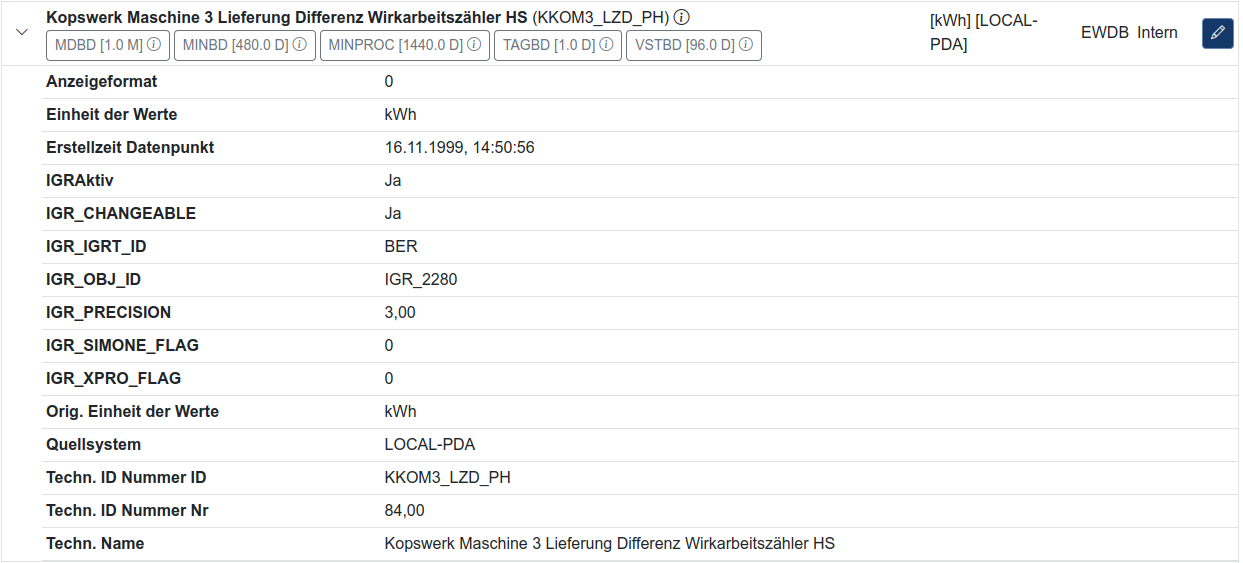
Abb. 3: Anzeige des generierten Bezeichners in der Datenpunktsuche
Der Datenpunkt wird über die vorher konfigurierten Metadaten repräsentiert - der Langname selbst wird fett gedruckt, die Annotationen in der Spalte weiter rechts angezeigt.